
Two Brains Are Better Than One: How Small + Large Language Models Supercharge Your Firm

Most firms don’t need “AI everywhere”—they need targeted help where time is routinely lost and capacity matters: intake triage, document sorting, deadline capture, and first‑pass drafting. To get the most out of AI for your practice, two brains are better than one. The optimal strategy is not complete reliance on a universal chatbot or AI application through the tools you already use. Rather, the true productively and intelligence unlock is a Small Language Model (SLM) combined with a Large Language Model (LLM). As with your staff, they have different roles. The SLM is your lightning‑fast specialist that lives on your own hardware and the LLM is your well‑read strategist in the cloud. Used together, they turn a pile of PDFs, emails, and orders into structured facts and polished prose with less drag on attorneys and staff.
Both an SLM and LLM use the same underlying AI architecture, but an LLM is trained on massive datasets with hundreds of billions of parameters, making it powerful but resource-intensive and usually cloud-based. An SLM, by contrast, is trained on fewer parameters—millions or a few billion—so it’s smaller, faster, and light enough to run on a local workstation or firm server. That “small” size doesn’t mean it’s less useful; it means the model is narrower and more specialized, well-suited for secure, repeatable, and confidential legal tasks inside the firm. Because an SLM can be local and controllable, you can safely point it at the firm’s archive of briefs, orders, transcripts, and email threads. It can classify matter types, extract entities (people, courts, dates, amounts), detect key clauses, normalize time‑entry text, and pull deadlines from orders—all at sub‑second latency. That structured output becomes a private, searchable index of your own work product. The practical effect is that the SLM unlocks value already in your database while keeping privileged material inside your firewall, which helps you meet confidentiality and supervision duties without changing your tech stack.
An LLM is larger and more capable at open‑ended reasoning and drafting. It shines when you want a first‑pass client letter from messy facts, a memo that compares arguments across jurisdictions, or a deposition outline that weaves together emails, transcripts, and key exhibits. The trade‑off is cost and latency: you typically access it via a secure enterprise API, and you should reserve it for the moments when judgment, synthesis, and tone matter. Your SLM sets the table and your LLM helps with your high level output.
The real magic is the handoff. Let the SLM do the heavy lifting up front—classify documents, extract facts, and build a retrieval index over your firm’s corpus (retrieval‑augmented generation, or RAG). Then, when you call the LLM, you don’t ask it to “remember the world.” You hand it only the relevant snippets your SLM already pulled from your own files. The LLM writes with citations back to those snippets, so attorneys can skim sources and accept or edit quickly. In practice this looks like: client email arrives → SLM identifies matter type, parties, and deadlines and files everything correctly → LLM turns the extracted facts and a couple of retrieved templates into a draft letter → attorney reviews, adds judgment, and sends. The same pattern works for discovery (auto‑tag → retrieve exemplars → draft strategy) and for docket hygiene (extract → verify → calendar).
Running the SLM on‑site vastly improves performance and reduces cost, but it also helps you secure client confidentiality and reduces reliance on the data standards and hack risks of outside companies. Because sensitive material never leaves your environment by default, you can enforce redaction of PII or privileged content before any external call, maintain audit logs for supervision, and keep a bright line between consumer chat tools and enterprise workflows. Combined with RAG, the LLM’s outputs are grounded in your actual documents, which reduces hallucinations and makes it obvious what was relied on and why. That combination—local SLM as privacy front end, LLM as reasoning back end—aligns with confidentiality, competence, and supervision obligations while giving partners the speed and polish they actually want.
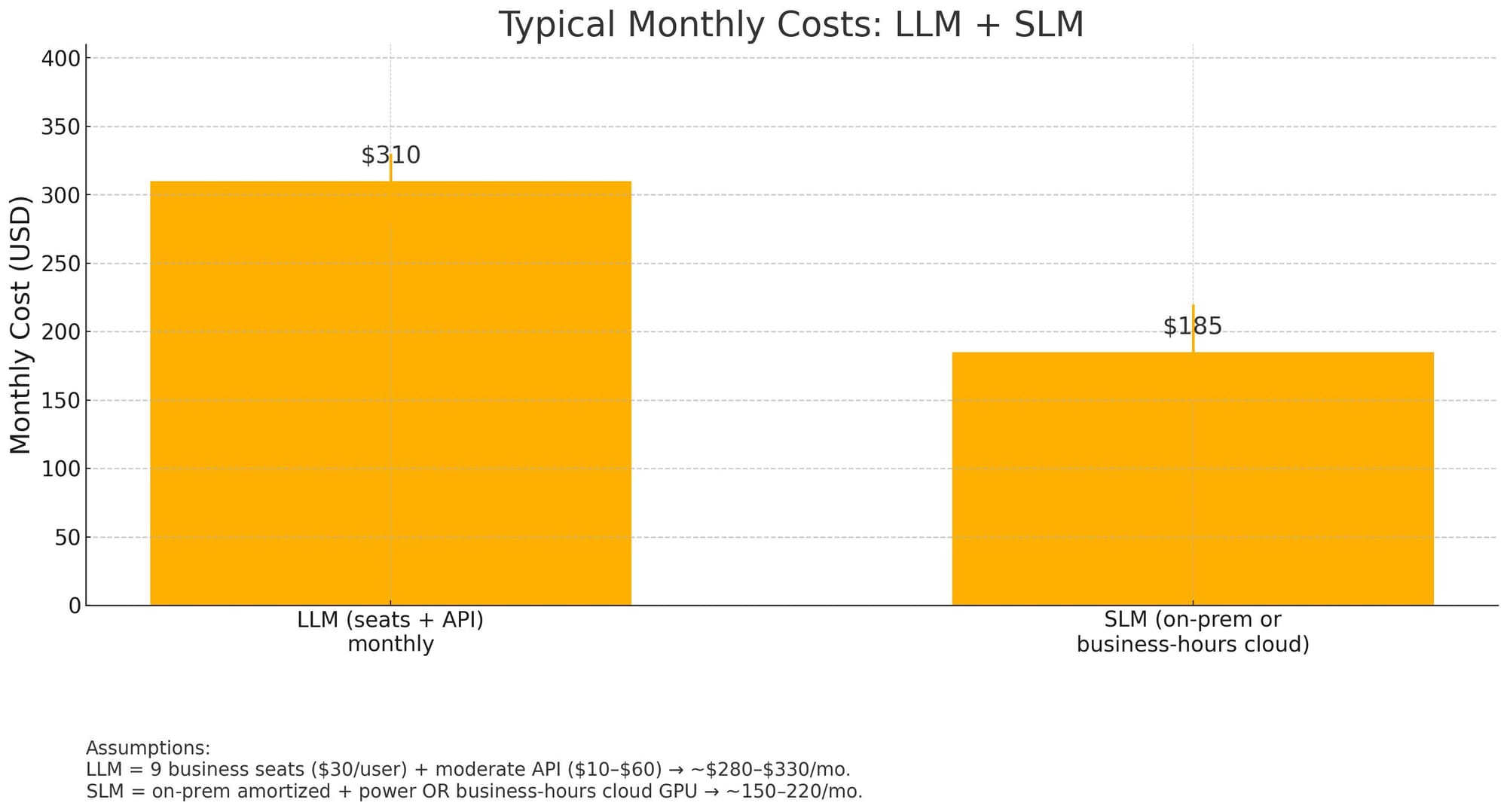
Typically, the SLM operates at low cost and helps reduce the total software costs of overall. The LLM license and SLM can operate at well under $100 per month per seat (massively increasing productivity while also eliminating the need for other software currently in the budget). For a five-person firm with 4 staff, both models can run for around $60 per month per seat.
Firms that deploy this hybrid approach see gains where it counts: intake replies go out faster without sacrificing tone, deadlines are captured earlier with fewer misses, discovery reviews start organized instead of chaotic, and first‑pass drafts arrive with sources attached so edits are surgical rather than rewrites. Of course, all of this functionality creates new workflows. All firms should take an incremental approach to full roll-out of these features so lawyers gain confidence in the tools and firms can dial in the best use on a practical level.



